前言
今天主要分享如何利用爬蟲爬取區塊鏈瀏覽器上的交易列表數據。
原因
dune上沒有bsc鏈上的轉賬明細數據表。Footprint Analytics上現有的bsc_transactions表transfer_type粒度不夠。
環境
python 3.7
數據存儲:mysql 5.7
緩存:redis 6.2.6
開發工具:pycharm
思路
(1)所有協議、合約、swap地址轉賬信息全爬不太實際,對存儲要求比較高。所以針對需要分析的協議,專門去爬取對應智能合約轉賬是個不錯的選擇。
(2)區塊鏈瀏覽器肯定是有反爬機制的。所以在代理選擇上,要選擇國外的代理。國內的代理都訪問不到,具體原因你懂的。本文中不涉及代理部分,因為國外的代理廠家之前沒有了解過。不過即使是上代理,對代碼層面改動也比較小
(3)采用了urllib同步請求 + 范圍內隨機時長程序休眠。減少了被風控的概率。但是也降低了爬蟲的效率。
后面再研究用scrapy或異步請求 [1]
[1] 同步:請求發送后,需要接受到返回的消息后,才進行下一次發送。異步:不需要等接收到返回的消息。
實現
找到需要爬取合約的具體地址:
第一頁
http://bscscan.com/txs?a=0xbd3bd95529e0784ad973fd14928eedf3678cfad8
第二頁
https://bscscan.com/txs?a=0xbd3bd95529e0784ad973fd14928eedf3678cfad8&p=2
第三頁
https://bscscan.com/txs?a=0xbd3bd95529e0784ad973fd14928eedf3678cfad8&p=3
….
可以知道 p = ?就代表頁數。
然后F12 點擊“網絡”,刷新界面,查看網絡請求信息。
主要查看,網頁上顯示的數據,是哪個文件響應的。以什麼方式響應的,請求方法是什麼
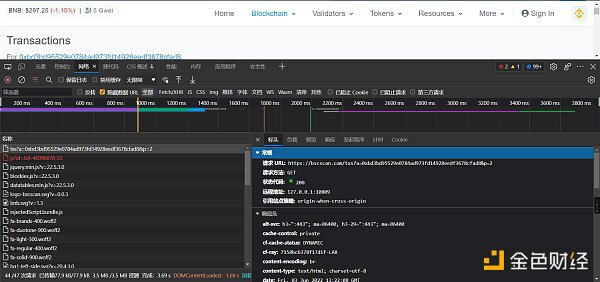

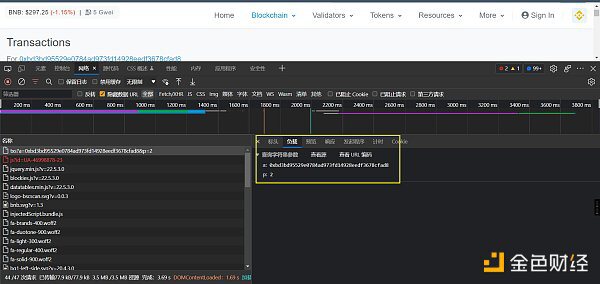
如何驗證呢,就是找一個txn_hash在響應的數據里面按ctrl + f去搜索,搜索到了說明肯定是這個文件返回的。
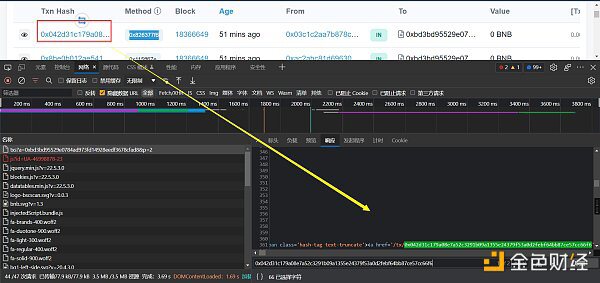
查看響應的數據,是html的格式。在python里面,處理html數據,個人常用的是xpath(當然,如果更擅長BeautifulSoup也可以)
在python里面安裝相關的依賴
pip install lxml ‐i https://pypi.douban.com/simple
同時在瀏覽器上安裝xpath插件,它能更好的幫助我們獲到網頁中元素的位置
XPath Helper – Chrome 網上應用店 (google.com)
然后就可以通過插件去定位了,返回的結果是list
**注:**瀏覽器看到的網頁都是瀏覽器幫我們渲染好的。存在在瀏覽器中能定位到數據,但是代碼中取不到值的情況,這時候可以通過鼠標右鍵-查看網頁源碼,然后搜索實現
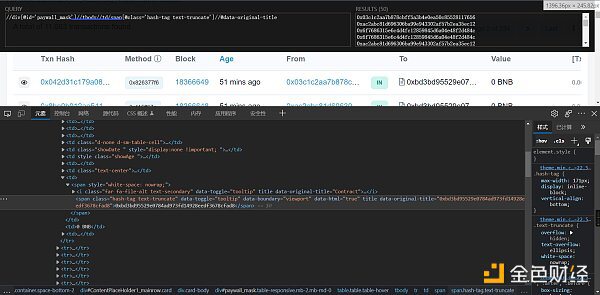
# 請求和xpath定位具體實現代碼: def start_spider(page_number): url_base = 'http://bscscan.com /txs?a=0xbd3bd95529e0784ad973fd14928eedf3678cfad8&' # 請求頭 headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36', 'referer': 'https://bscscan.com/txs?a=0xbd3bd95529e0784ad973fd14928eedf3678cfad8' } # 需要傳入的參數 data = { 'p': page_number } # 將參數轉為Unicode編碼格式 unicode_data = urllib.parse.urlencode(data) # 拼接網址 # http://bscscan.com/txs?a=0xbd3bd95529e0784ad973fd14928eedf3678cfad8 url = url_base + unicode_data # 自定義request對象 request = urllib.request.Request(url=url, headers=headers) # 模擬瀏覽器發送請求 response = urllib.request.urlopen(request) # 將返回的數據利用lxml轉為 tree = etree.HTML(response.read().decode('utf‐8')) # //div[@id='paywall_mask']//tbody//td//span/a[@class='myFnExpandBox_searchVal']/text() txn_hash_list = tree.xpath(https://div[@id='paywall_mask']//tbody//td//span/a[@class='myFnExpandBox_searchVal']/text()) # //div[@id='paywall_mask']//tbody//td//span[@class='u-label u-label--xs u-label--info rounded text-dark text-center']/text() method_list = tree.xpath( https://div[@id='paywall_mask']//tbody//td//span[@class='u-label u-label--xs u-label--info rounded text-dark text-center']/text()) # //div[@id='paywall_mask']//tbody//td[@class='d-none d-sm-table-cell']//text() block_list = tree.xpath(https://div[@id='paywall_mask']//tbody//td[@class='d-none d-sm-table-cell']//text()) # //div[@id='paywall_mask']//tbody//td[@class='showAge ']/span/@title age_list = tree.xpath(https://div[@id='paywall_mask']//tbody//td[@class='showAge ']/span/@title) # //div[@id='paywall_mask']//tbody//td/span[@class='hash-tag text-truncate']/@title from_list = tree.xpath( https://div[@id='paywall_mask']//tbody//td/span[@class='hash-tag text-truncate']/@title) # //div[@id='paywall_mask']//tbody//td[@class='text-center']/span/text() transfer_type_list = tree.xpath(https://div[@id='paywall_mask']//tbody//td[@class='text-center']/span/text()) # //div[@id='paywall_mask']//tbody//td/span/span[@class='hash-tag text-truncate']//text() to_list = tree.xpath(https://div[@id='paywall_mask']//tbody//td/span/span[@class='hash-tag text-truncate']//text()) # //div[@id='paywall_mask']//tbody//td/span[@class='small text-secondary']/text()[2] transfer_free_list = tree.xpath( https://div[@id='paywall_mask']//tbody//td/span[@class='small text-secondary']/text()[2])
然后就是利用redis,對txn_hash去重,去重的原因是防止一條數據被爬到了多次
def add_txn_hash_to_redis(txn_hash): red = redis.Redis(host='根據你自己的配置', port=6379, db=0) res = red.sadd('txn_hash:txn_set', get_md5(txn_hash)) # 如果返回0,這說明插入不成功,表示有重復 if res == 0: return False else: return True # 將mmsi進行哈希,用哈希去重更快 def get_md5(txn_hash): md5 = hashlib.md5() md5.update(txn_hash.encode('utf-8')) return md5.hexdigest()
最后一個需要考慮的問題:交易是在增量了,也就是說,當前第二頁的數據,很可能過會就到第三頁去了。對此我的策略是不管頁數的變動。一直往下爬。全量爬完了,再從第一頁爬新增加的交易。直到遇到第一次全量爬取的txn_hash
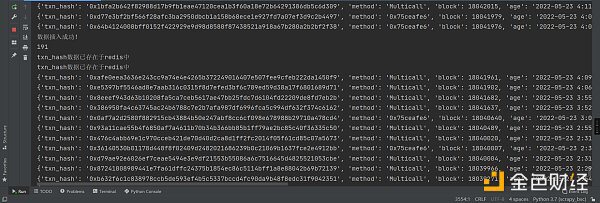
最后就是存入到數據庫了。這個沒啥好說的。
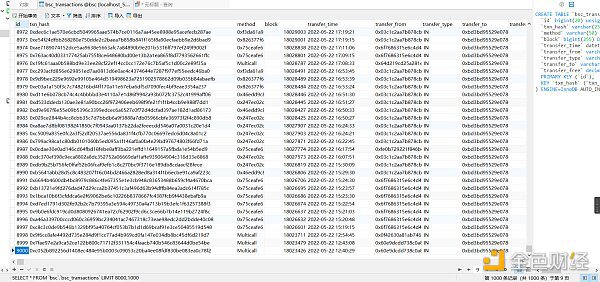
以上就可以拿到轉賬列表中的txn_hash,后面還要寫一個爬蟲深入列表里面,通過txn_hash去爬取詳情頁面的信息。這個就下個文章再說,代碼還沒寫完。
發文者:鏈站長,轉載請註明出處:https://www.jmb-bio.com/4174.html
 微信扫一扫
微信扫一扫